
For data to be truly considered open, the data must be complete in regard to the content of the data itself and in regard to the metadata describing the information that an open data publisher is releasing. Creating a comprehensive open data catalogue is an effective way for ensuring that published open data is accompanied by the minimum required amount of metadata.
Even though many government entities in Oman have published open data in the past, the majority of these government entities do not include a sufficient description of the data they publish, and instead upload a collection of Excel files that do not include any details other than the file name.
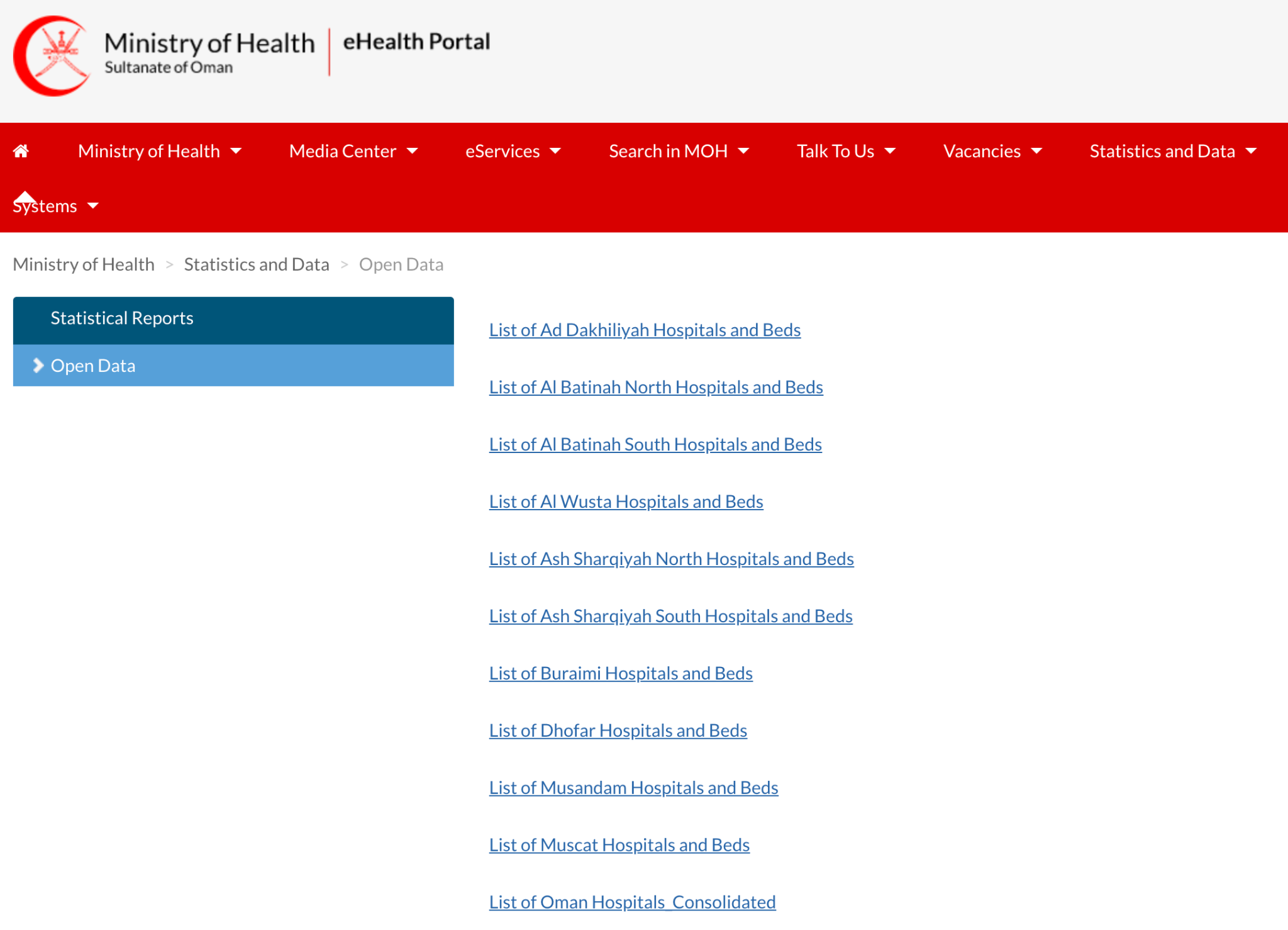
This webpage shows an example of a government entity publishing a collection of files without any metadata or other useful information to provide context for the open data it publishes.
It is highly recommended that an entity creates an open data catalogue to ensure that the data is properly identified and easily accessible. Such a catalogue should reasonably be made published on the internet and should be the primary method for enabling users to locate and download the data.
In particular, this open data catalogue should include separate entities for each dataset covering the following elements:

Title
The catalogue should include a short title describing the dataset in question.

Description
The catalogue should include a brief explanation of the contents of the dataset, a description of why this data is significant, and the manner in which it was collected.

Period Covered
If applicable, the catalogue should provide details of the time period covered by the data. For example, if the data relates to COVID-19 deaths, the data should indicate that the data covers the period from March 2020 to January 2021 (as an illustration).

Update Frequency
If the data is expected to be updated, the data catalogue should indicate to the user how often this data would be updated. For example, daily, monthly, yearly, or any other frequency. If the data is supplied in real-time, the catalogue should also indicate this. Certain datasets, such as maps or other reference datasets, might not be updated on a regular basis or at all, and this information should also be indicated to the user.

File Format
In addition to the importance of publishing open data in a machine-readable format, it is equally important to indicate to the end-user what format exactly is available for download. Examples include CSV, XML, and JSON.

Name and Contact Details of Person or Department
For big organisations, it is important for the end-user to have the contact details of the person or department responsible for the dataset in question. This is useful from a data validity point of view, but can also assist end-user that seek clarifications and those who would like to report errors found in the data.
Metadata
In addition to the general description details of the dataset, the catalogue should include a description of each field in the dataset explaining the content of that field and the format of the data provided in that field. For example, if the dataset has a name field, the catalogue must indicate if this will be provided in the Arabic or English language, and if the dataset has a date field, the catalogue must indicate the date format in which this will be provided (e.g. YYYY-MM-DD).
Example
The points explained on page can be used to transform the example shown above to become a more useful listing as follows:
Dataset Description
| Title | Number of hospitals and beds in the Governorate of Dakhiliya |
| Description | This dataset provides the details of the hospitals in the Governorate of Dakhilya with the details of the number of beds in each hospital. |
| Period Covered | This dataset captures the state of hospitals in this region in December 2020. |
| Update Frequency | Yearly at the end of every year. |
| File Format | XLSX |
| Contact | Directorate General of Health in the Governorate of Dakhiliya. Name: XXXX Email: [email protected] |
Metadata
| Field | Description |
| Wilayat | The name of the Wiyalat in English. |
| Hospital Name – AR | The name of the hospital in Arabic. |
| Hospital Name – EN | The name of the hospital in English. |
| Beds | The number of beds in the hospital. |
Each published dataset requires an individual description that provides the general information on the dataset, as well as an individual metadata table that explains what each field in the dataset refers to.